Monster SCALE Summit 2026 (Sponsored)Extreme Scale Engineering | Online | March 11-12
Your free ticket to Monster SCALE Summit is waiting — 30+ engineering talks on data-intensive applications Monster SCALE Summit is a virtual conference that’s all about extreme-scale engineering and data-intensive applications. Engineers from Discord, Disney, LinkedIn, Pinterest, Rivian, American Express, Google, ScyllaDB, and more will be sharing 30+ talks on topics like:
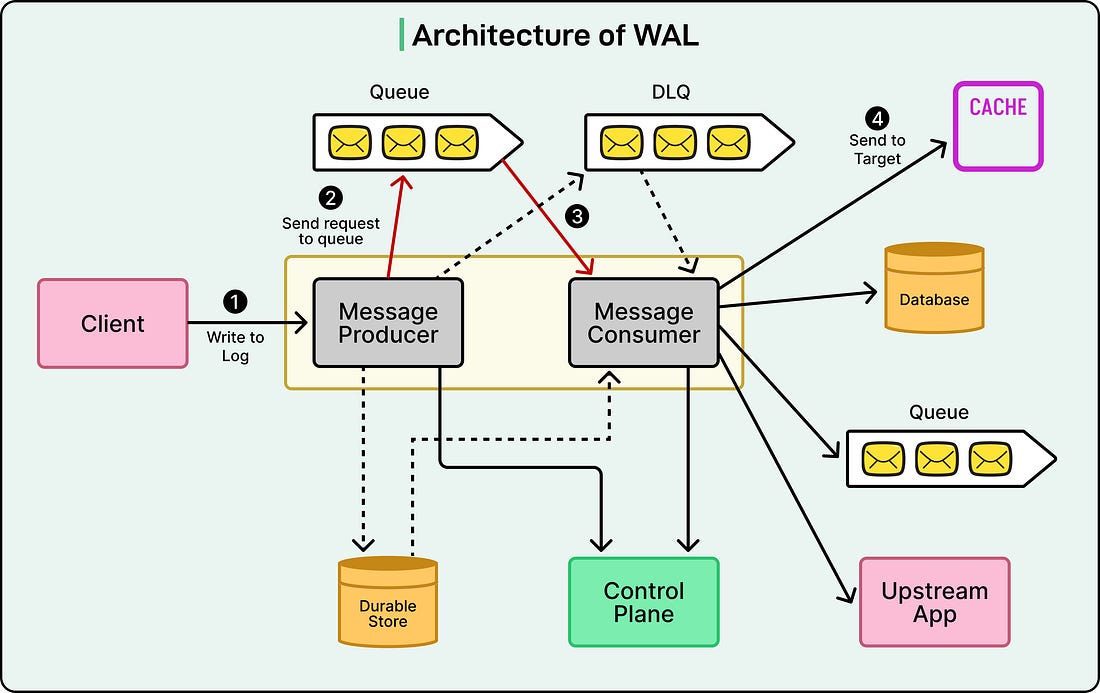
Don’t miss this chance to connect with 20K of your peers designing, implementing, and optimizing data-intensive applications – for free, from anywhere. Register now to save your seat, and become eligible for an early bird swag pack! Disclaimer: The details in this post have been derived from the details shared online by the Netflix Engineering Team. All credit for the technical details goes to the Netflix Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them. Netflix processes an enormous amount of data every second. Each time a user plays a show, rates a movie, or receives a recommendation, multiple databases and microservices work together behind the scenes. This functionality is supported using hundreds of independent systems that must stay consistent with each other. When something goes wrong in one system, it can quickly create a ripple effect across the platform. Netflix’s engineering team faced several recurring issues that threatened the reliability of their data. Some of these included accidental data corruption after schema changes, inconsistent updates between storage systems such as Apache Cassandra and Elasticsearch, and message delivery failures during transient outages. At times, bulk operations like large delete jobs even caused key-value database nodes to run out of memory. On top of that, some databases lacked built-in replication, which meant that regional failures could lead to permanent data loss. Each engineering team tried to handle these issues differently. One team would build custom retry systems, another would design its own backup strategy, and yet another would use Kafka directly for message delivery. While these solutions worked individually, they created complexity and inconsistent guarantees across Netflix’s ecosystem. Over time, this patchwork approach increased maintenance costs and made debugging more difficult. To fix this, Netflix built a Write-Ahead Log system to act as a single, resilient foundation for data reliability. The WAL standardizes how data changes are recorded, stored, and replayed across services. In simple terms, it captures every change before it is applied to the database, so that even if something fails midway, no information is lost. In this article, we will look at how Netflix built this WAL and the challenges it faced. What is a Write-Ahead Log?At its core, a Write-Ahead Log is a simple but powerful idea. It is a system that keeps a record of every change made to data before those changes are applied to the actual database. You can think of it like keeping a journal of all the actions you plan to take. Even if something goes wrong during the process, you still have that journal to remind you exactly what you were doing, so you can pick up right where you left off. In practical terms, when an application wants to update or delete information in a database, it first writes that intention to the WAL. Only after the entry has been safely recorded does the database proceed with the operation. This means that if a server crashes or a network connection drops, Netflix can replay the operations from the WAL and restore everything to the correct state. Nothing is lost, and the data remains consistent across systems. Netflix’s version of WAL is not tied to a single database or service. It is distributed, meaning it runs across multiple servers to handle massive volumes of data. It is also pluggable, allowing it to connect easily to various technologies, such as Kafka, Amazon SQS, Apache Cassandra, and EVCache. This flexibility allowed the Netflix engineering team to use the same reliability framework for different types of workloads, whether it’s storing cached video metadata, user preferences, or system logs. See the diagram below:
The WAL provides several key benefits that make Netflix’s data platform more resilient:
The WAL APINetflix’s Write-Ahead Log system provides a simple interface for the developers. Despite the complexity of what happens behind the scenes, the API that developers interact with contains only one main operation called WriteToLog. This API acts as the entry point for any application that wants to record a change. The structure looks something like this: rpc WriteToLog (WriteToLogRequest) returns (WriteToLogResponse); Even though this may look technical, the idea is straightforward. A service sends a request to WAL describing what it wants to write and where that data should go. WAL then processes the request, stores it safely, and responds with information about whether the operation was successful. The request contains four main parts:
The response from WAL is equally simple:
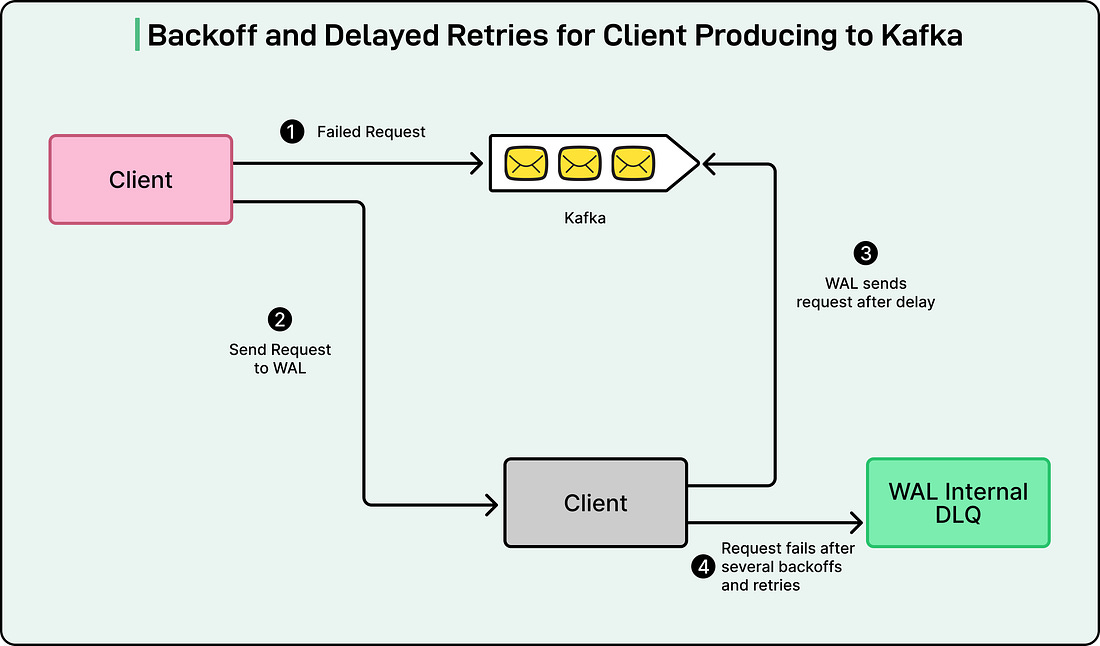
Each namespace in WAL has its own configuration that defines how it behaves. For example, one namespace may be set up to use Kafka for high-speed streaming, while another might rely on Amazon SQS for delayed message delivery. The team can adjust settings like retry counts, backoff times, and delay intervals depending on what each application needs. Different Use Cases of the WALNetflix designed the WAL system to be flexible enough to support many different situations, which they refer to as personas. Each persona represents a unique way that WAL is used within the company’s data ecosystem. Let’s look at a few of the main ones to understand how this system adapts to different needs. 1 - Delayed QueuesThis use case comes from the Product Data Systems (PDS) team, which handles a lot of real-time data updates. In large-scale systems like Netflix, failures are inevitable. Sometimes, a downstream service such as Kafka or a database might be temporarily unavailable due to network issues or maintenance. Instead of losing messages or forcing engineers to manually retry failed operations, WAL automatically steps in. When a system failure occurs, WAL uses Amazon SQS (Simple Queue Service) to delay messages and retry them later. See the diagram below for backoff and delayed retries for clients producing to Kafka:
Here’s how it works in simple terms:
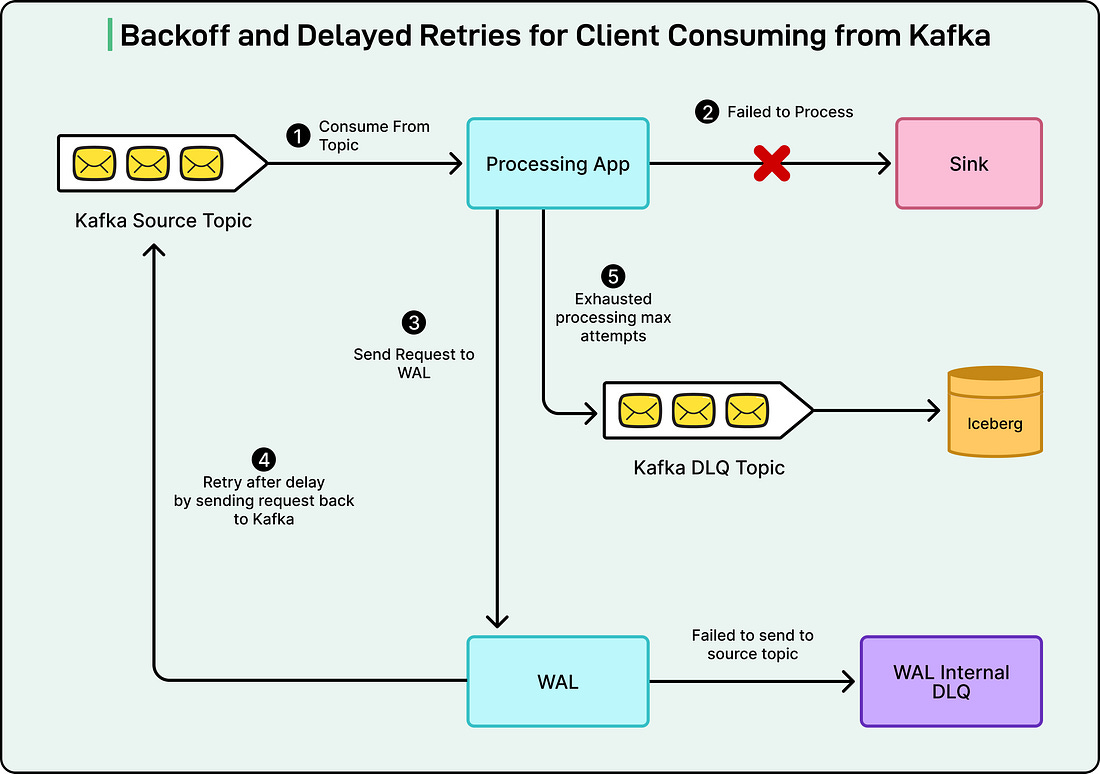
The diagram below shows the backoff and delayed retries for clients consuming from Kafka:
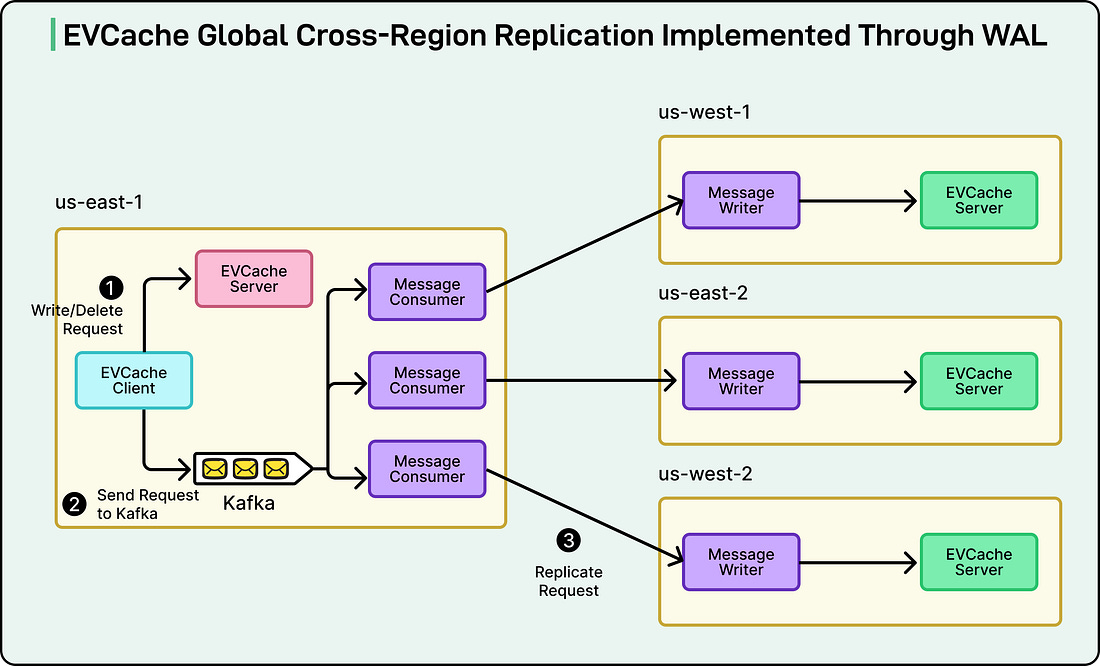
This approach saves engineers a lot of time and prevents cascading failures that might otherwise spread across the platform. 2 - Cross-Region ReplicationAnother major use case is data replication across Netflix’s global regions. The company’s caching system, EVCache, stores frequently accessed data to make streaming fast and reliable. However, since Netflix operates worldwide, the same data needs to exist in multiple regions. WAL makes this replication seamless by using Kafka under the hood. Whenever data is written or deleted in one region, WAL captures that event and sends it to other regions. The consumers in each region then replay the same operations locally, ensuring that all copies of the data stay synchronized. See the diagram below:
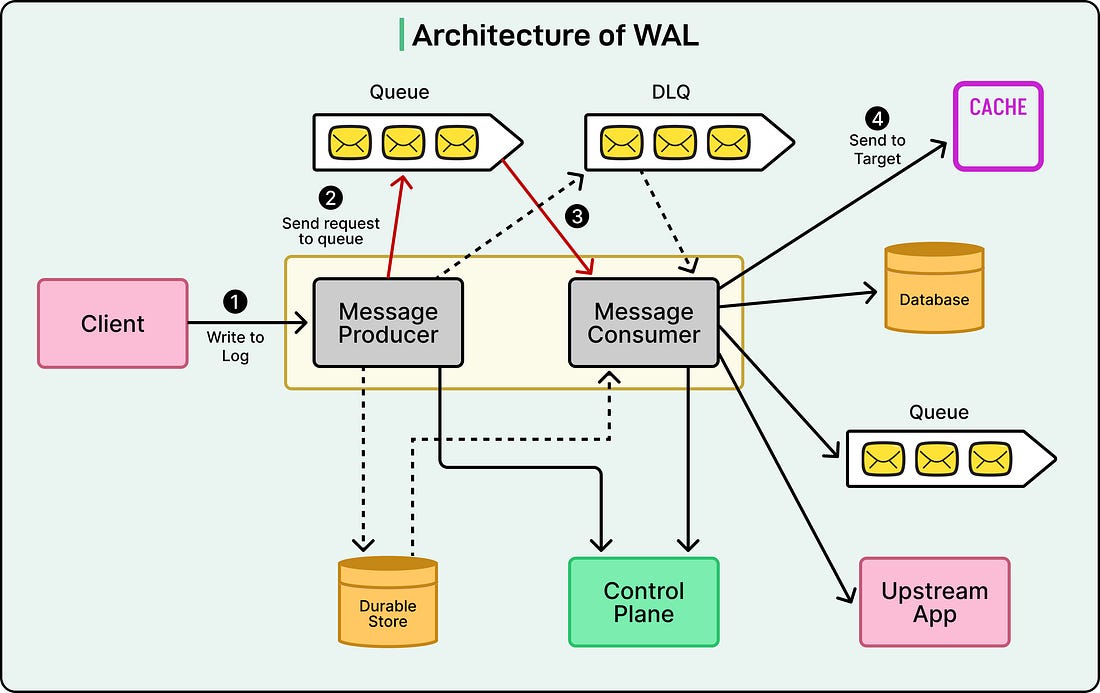
In simpler terms, WAL acts like a reliable postman, making sure every region receives the same “letters” (data updates), even if network disruptions occur. This system keeps Netflix consistent around the world. Users in India, Europe, or the US all see the same data at nearly the same time. 3 - Multi-Partition MutationsThe final example involves Netflix’s Key-Value data service, which stores information in systems like Apache Cassandra. Sometimes, a single operation might need to update data spread across multiple partitions or tables. Handling these multi-part changes is tricky, especially in distributed systems, because a failure in one partition can leave others out of sync. WAL solves this problem by ensuring atomicity, meaning that either all the changes succeed or all are retried until they do. To achieve this, Netflix’s WAL combines Kafka for message delivery with durable storage for reliability. This setup functions similarly to a two-phase commit, a well-known database technique that guarantees data consistency across multiple locations. In short, WAL coordinates complex updates so that Netflix’s data remains correct, even when multiple systems are involved. Internal ArchitectureTo understand how Netflix’s Write-Ahead Log (WAL) works behind the scenes, it helps to break it down into its main building blocks. See the diagram below:
The system is made up of several key components that work together to move data safely from one place to another while keeping everything flexible and resilient.
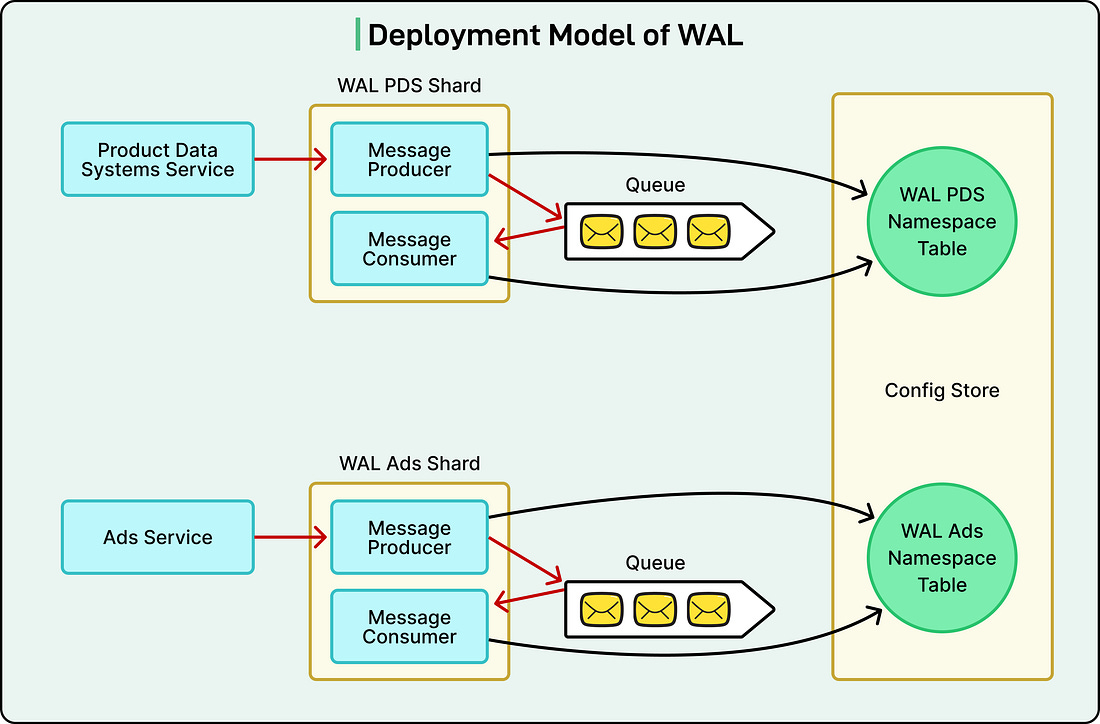
Deployment ModelThe way Netflix deploys its Write-Ahead Log (WAL) system is just as important as how it works internally. To handle billions of data operations across many teams and services, Netflix needed a platform that could scale easily, stay secure, and run reliably across regions. To achieve this, WAL is deployed on top of Netflix’s Data Gateway Infrastructure. This infrastructure acts as a foundation that gives WAL several built-in advantages right out of the box:
Netflix organizes WAL deployments into shards. A shard is an independent deployment that serves a specific group of applications or use cases. For example, one shard might handle the Ads service, another might handle Gaming data, and so on. This separation prevents the “noisy neighbor” problem, where one busy service could slow down others running on the same system. Inside each shard, there can be multiple namespaces, each with its own configuration and purpose. These configurations are stored in a globally replicated SQL database, ensuring they are always available and consistent, even if a region goes offline. See the diagram below for the deployment model of WAL at Netflix:
ConclusionSeveral key design principles shaped the success of WAL. The first is its pluggable architecture, which allows Netflix to switch between different technologies, such as Kafka or Amazon SQS, without changing application code. This flexibility ensures that teams can choose the most suitable underlying system for their specific use cases while relying on the same core framework. Another principle is the reuse of existing infrastructure. Instead of building everything from scratch, Netflix built WAL on top of its already established systems, like the Data Gateway platform and Key-Value abstractions. This approach saved development time and allowed the new system to fit naturally into the company’s broader data architecture. Equally important is the separation of concerns between producers and consumers. Because these components scale independently, Netflix can adjust each one based on traffic patterns or system load. This independence allows WAL to handle massive spikes in demand without service degradation. Finally, Netflix recognizes that even a system designed for reliability must consider its own limits. The team continuously evaluates trade-offs, such as dealing with slow consumers or managing backpressure during heavy traffic. Techniques like partitioning and controlled retries are essential to keeping the system stable. Looking ahead, Netflix plans to enhance WAL further. Future improvements include adding secondary indices to the Key-Value service, which will make data retrieval faster and more efficient, and supporting multi-target writes, allowing a single operation to send data to multiple destinations, such as a database and a backup system at the same time. References: SPONSOR USGet your product in front of more than 1,000,000 tech professionals. Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases. Space Fills Up Fast - Reserve Today Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
|
How Netflix Built a Distributed Write Ahead Log For Its Data Platform


Posted by WE BRING YOU THE BEST!
 VHAVENDA I.T SOLUTIONS
VHAVENDA I.T SOLUTIONS













0 Comments
VHAVENDA IT SOLUTIONS AND SERVICES WOULD LIKE TO HEAR FROM YOU🫵🏼🫵🏼🫵🏼🫵🏼